# Javascript 学习总结
# 一、数据类型
- JavaScript 有哪些数据类型,它们的区别?
JavaScript 共有八种数据类型,分别是 Undefined、Null、Boolean、Number、String、Object、Symbol、BigInt。
其中 Symbol 和 BigInt 是 ES6 中新增的数据类型:
- Symbol 代表创建后独一无二且不可变的数据类型,它主要是为了解决可能出现的全局变量冲突的问题。
- BigInt 是一种数字类型的数据,它可以表示任意精度格式的整数,使用 BigInt 可以安全地存储和操作大整数,即使这个数已经超出了 Number 能够表示的安全整数范围。
这些数据可以分为原始数据类型和引用数据类型:
- 栈:原始数据类型(Undefined、Null、Boolean、Number、String)
- 堆:引用数据类型(对象、数组和函数)
两种类型的区别在于存储位置的不同:
- 原始数据类型直接存储在栈(stack)中的简单数据段,占据空间小、大小固定,属于被频繁使用数据,所以放入栈中存储;
- 引用数据类型存储在堆(heap)中的对象,占据空间大、大小不固定。如果存储在栈中,将会影响程序运行的性能;引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
堆和栈的概念存在于数据结构和操作系统内存中,在数据结构中:
- 在数据结构中,栈中数据的存取方式为先进后出。
- 堆是一个优先队列,是按优先级来进行排序的,优先级可以按照大小来规定。
在操作系统中,内存被分为栈区和堆区:
- 栈区内存由编译器自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
- 堆区内存一般由开发着分配释放,若开发者不释放,程序结束时可能由垃圾回收机制回收。
- 数据类型检测的方式有哪些
(1)typeof
console.log(typeof 2); // number | |
console.log(typeof true); // boolean | |
console.log(typeof 'str'); // string | |
console.log(typeof []); // object | |
console.log(typeof function(){}); // function | |
console.log(typeof {}); // object | |
console.log(typeof undefined); // undefined | |
console.log(typeof null); // object |
其中数组、对象、null 都会被判断为 object,其他判断都正确。
(2)instanceof
instanceof 可以正确判断对象的类型,其内部运行机制是判断在其原型链中能否找到该类型的原型。
console.log(2 instanceof Number); // false | |
console.log(true instanceof Boolean); // false | |
console.log('str' instanceof String); // false | |
console.log([] instanceof Array); // true | |
console.log(function(){} instanceof Function); // true | |
console.log({} instanceof Object); // true |
可以看到,instanceof 只能正确判断引用数据类型,而不能判断基本数据类型。instanceof 运算符可以用来测试一个对象在其原型链中是否存在一个构造函数的 prototype 属性。
(3) constructor
console.log((2).constructor === Number); // true | |
console.log((true).constructor === Boolean); // true | |
console.log(('str').constructor === String); // true | |
console.log(([]).constructor === Array); // true | |
console.log((function() {}).constructor === Function); // true | |
console.log(({}).constructor === Object); // true |
constructor 有两个作用,一是判断数据的类型,二是对象实例通过 constrcutor 对象访问它的构造函数。
需要注意,如果创建一个对象来改变它的原型,constructor 就不能用来判断数据类型了:
function Fn(){}; | |
Fn.prototype = new Array(); | |
var f = new Fn(); | |
console.log(f.constructor===Fn); // false | |
console.log(f.constructor===Array); // true |
(4)Object.prototype.toString.call()
Object.prototype.toString.call () 使用 Object 对象的原型方法 toString 来判断数据类型:
var a = Object.prototype.toString; | |
console.log(a.call(2)); | |
console.log(a.call(true)); | |
console.log(a.call('str')); | |
console.log(a.call([])); | |
console.log(a.call(function(){})); | |
console.log(a.call({})); | |
console.log(a.call(undefined)); | |
console.log(a.call(null)); |
同样是检测对象 obj 调用 toString 方法,obj.toString () 的结果和 Object.prototype.toString.call (obj) 的结果不一样,这是为什么?
这是因为 toString 是 Object 的原型方法,而 Array、function 等类型作为 Object 的实例,都重写了 toString 方法。不同的对象类型调用 toString 方法时,根据原型链的知识,调用的是对应的重写之后的 toString 方法(function 类型返回内容为函数体的字符串,Array 类型返回元素组成的字符串…),而不会去调用 Object 上原型 toString 方法(返回对象的具体类型),所以采用 obj.toString () 不能得到其对象类型,只能将 obj 转换为字符串类型;因此,在想要得到对象的具体类型时,应该调用 Object 原型上的 toString 方法。
- 判断数组的方式有哪些
- 通过 Object.prototype.toString.call () 做判断
Object.prototype.toString.call(obj).slice(8,-1) === 'Array'; |
- 通过原型链做判断
obj.__proto__ === Array.prototype; |
- 通过 ES6 的 Array.isArray () 做判断
Array.isArrray(obj); |
- 通过 instanceof 做判断
obj instanceof Array |
- 通过 Array.prototype.isPrototypeOf
Array.prototype.isPrototypeOf(obj) |
- null 和 undefined 区别
首先 Undefined 和 Null 都是基本数据类型,这两个基本数据类型分别都只有一个值,就是 undefined 和 null。
undefined 代表的含义是未定义,null 代表的含义是空对象。一般变量声明了但还没有定义的时候会返回 undefined,null 主要用于赋值给一些可能会返回对象的变量,作为初始化。
undefined 在 JavaScript 中不是一个保留字,这意味着可以使用 undefined 来作为一个变量名,但是这样的做法是非常危险的,它会影响对 undefined 值的判断。我们可以通过一些方法获得安全的 undefined 值,比如说 void 0。
当对这两种类型使用 typeof 进行判断时,Null 类型化会返回 “object”,这是一个历史遗留的问题。当使用双等号对两种类型的值进行比较时会返回 true,使用三个等号时会返回 false。
- typeof null 的结果是什么,为什么?
typeof null 的结果是 Object。
在 JavaScript 第一个版本中,所有值都存储在 32 位的单元中,每个单元包含一个小的 类型标签 (1-3 bits) 以及当前要存储值的真实数据。类型标签存储在每个单元的低位中,共有五种数据类型:
000: object - 当前存储的数据指向一个对象。 | |
1: int - 当前存储的数据是一个 31 位的有符号整数。 | |
010: double - 当前存储的数据指向一个双精度的浮点数。 | |
100: string - 当前存储的数据指向一个字符串。 | |
110: boolean - 当前存储的数据是布尔值。 |
如果最低位是 1,则类型标签标志位的长度只有一位;如果最低位是 0,则类型标签标志位的长度占三位,为存储其他四种数据类型提供了额外两个 bit 的长度。
有两种特殊数据类型:
- undefined 的值是 (-2) 30 (一个超出整数范围的数字);
- null 的值是机器码 NULL 指针 (null 指针的值全是 0)
那也就是说 null 的类型标签也是 000,和 Object 的类型标签一样,所以会被判定为 Object。
- intanceof 操作符的实现原理及实现
instanceof 运算符用于判断构造函数的 prototype 属性是否出现在对象的原型链中的任何位置。
function myInstanceof(left, right) { | |
// 获取对象的原型 | |
let proto = Object.getPrototypeOf(left) | |
// 获取构造函数的 prototype 对象 | |
let prototype = right.prototype; | |
// 判断构造函数的 prototype 对象是否在对象的原型链上 | |
while (true) { | |
if (!proto) return false; | |
if (proto === prototype) return true; | |
// 如果没有找到,就继续从其原型上找,Object.getPrototypeOf 方法用来获取指定对象的原型 | |
proto = Object.getPrototypeOf(proto); | |
} | |
} |
- 为什么 0.1+0.2 ! == 0.3,如何让其相等
在开发过程中遇到类似这样的问题:
let n1 = 0.1, n2 = 0.2 | |
console.log(n1 + n2) // 0.30000000000000004 |
这里得到的不是想要的结果,要想等于 0.3,就要把它进行转化:
(n1 + n2).toFixed(2) // 注意,toFixed 为四舍五入 |
toFixed (num) 方法可把 Number 四舍五入为指定小数位数的数字。那为什么会出现这样的结果呢?
计算机是通过二进制的方式存储数据的,所以计算机计算 0.1+0.2 的时候,实际上是计算的两个数的二进制的和。0.1 的二进制是 0.0001100110011001100...(1100 循环),0.2 的二进制是:0.00110011001100...(1100 循环),这两个数的二进制都是无限循环的数。那 JavaScript 是如何处理无限循环的二进制小数呢?
一般我们认为数字包括整数和小数,但是在 JavaScript 中只有一种数字类型:Number,它的实现遵循 IEEE 754 标准,使用 64 位固定长度来表示,也就是标准的 double 双精度浮点数。在二进制科学表示法中,双精度浮点数的小数部分最多只能保留 52 位,再加上前面的 1,其实就是保留 53 位有效数字,剩余的需要舍去,遵从 “0 舍 1 入” 的原则。
根据这个原则,0.1 和 0.2 的二进制数相加,再转化为十进制数就是:0.30000000000000004。
下面看一下双精度数是如何保存的:
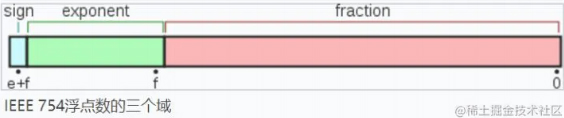
- 第一部分(蓝色):用来存储符号位(sign),用来区分正负数,0 表示正数,占用 1 位
- 第二部分(绿色):用来存储指数(exponent),占用 11 位
- 第三部分(红色):用来存储小数(fraction),占用 52 位
对于 0.1,它的二进制为:
0.00011001100110011001100110011001100110011001100110011001 10011... |
转为科学计数法(科学计数法的结果就是浮点数):
1.1001100110011001100110011001100110011001100110011001*2^-4 |
可以看出 0.1 的符号位为 0,指数位为 - 4,小数位为:
1001100110011001100110011001100110011001100110011001 |
那么问题又来了,指数位是负数,该如何保存呢?
IEEE 标准规定了一个偏移量,对于指数部分,每次都加这个偏移量进行保存,这样即使指数是负数,那么加上这个偏移量也就是正数了。由于 JavaScript 的数字是双精度数,这里就以双精度数为例,它的指数部分为 11 位,能表示的范围就是 0~2047,IEEE 固定双精度数的偏移量为 1023。
- 当指数位不全是 0 也不全是 1 时 (规格化的数值),IEEE 规定,阶码计算公式为 e-Bias。 此时 e 最小值是 1,则 1-1023= -1022,e 最大值是 2046,则 2046-1023=1023,可以看到,这种情况下取值范围是 - 1022~1013。
- 当指数位全部是 0 的时候 (非规格化的数值),IEEE 规定,阶码的计算公式为 1-Bias,即 1-1023= -1022。
- 当指数位全部是 1 的时候 (特殊值),IEEE 规定这个浮点数可用来表示 3 个特殊值,分别是正无穷,负无穷,NaN。 具体的,小数位不为 0 的时候表示 NaN;小数位为 0 时,当符号位 s=0 时表示正无穷,s=1 时候表示负无穷。
对于上面的 0.1 的指数位为 - 4,-4+1023 = 1019 转化为二进制就是:1111111011.
所以,0.1 表示为:
0 1111111011 1001100110011001100110011001100110011001100110011001 |
说了这么多,是时候该最开始的问题了,如何实现 0.1+0.2=0.3 呢?
对于这个问题,一个直接的解决方法就是设置一个误差范围,通常称为 “机器精度”。对 JavaScript 来说,这个值通常为 2-52,在 ES6 中,提供了 Number.EPSILON 属性,而它的值就是 2-52,只要判断 0.1+0.2-0.3 是否小于 Number.EPSILON,如果小于,就可以判断为 0.1+0.2 ===0.3
function numberepsilon(arg1,arg2){ | |
return Math.abs(arg1 - arg2) < Number.EPSILON; | |
} | |
console.log(numberepsilon(0.1 + 0.2, 0.3)); // true |
- 如何获取安全的 undefined 值?
因为 undefined 是一个标识符,所以可以被当作变量来使用和赋值,但是这样会影响 undefined 的正常判断。
表达式 void ___ 没有返回值,因此返回结果是 undefined。
void 并不改变表达式的结果,只是让表达式不返回值。因此可以用 void 0 来获得 undefined。
- typeof NaN 的结果是什么?
NaN 指 “不是一个数字”(not a number),NaN 是一个 “警戒值”(sentinel value,有特殊用途的常规值),用于指出数字类型中的错误情况,即 “执行数学运算没有成功,这是失败后返回的结果”。
typeof NaN; // "number" |
NaN 是一个特殊值,它和自身不相等,是唯一一个非自反(自反,reflexive,即 x === x 不成立)的值。而 NaN !== NaN 为 true。
- isNaN 和 Number.isNaN 函数的区别?
- 函数 isNaN 接收参数后,会尝试将这个参数转换为数值,任何不能被转换为数值的的值都会返回 true,因此非数字值传入也会返回 true ,会影响 NaN 的判断。
- 函数 Number.isNaN 会首先判断传入参数是否为数字,如果是数字再继续判断是否为 NaN ,不会进行数据类型的转换,这种方法对于 NaN 的判断更为准确。
- 其他值到字符串的转换规则?
- Null 和 Undefined 类型 ,null 转换为 "null",undefined 转换为 "undefined",
- Boolean 类型,true 转换为 "true",false 转换为 "false"。
- Number 类型的值直接转换,不过那些极小和极大的数字会使用指数形式。
- Symbol 类型的值直接转换,但是只允许显式强制类型转换,使用隐式强制类型转换会产生错误。
- 对普通对象来说,除非自行定义 toString () 方法,否则会调用 toString ()(Object.prototype.toString ())来返回内部属性 [[Class]] 的值,如 "[object Object]"。如果对象有自己的 toString () 方法,字符串化时就会调用该方法并使用其返回值。
- 其他值到数字值的转换规则?
- Undefined 类型的值转换为 NaN。
- Null 类型的值转换为 0。
- Boolean 类型的值,true 转换为 1,false 转换为 0。
- String 类型的值转换如同使用 Number () 函数进行转换,如果包含非数字值则转换为 NaN,空字符串为 0。
- Symbol 类型的值不能转换为数字,会报错。
- 对象(包括数组)会首先被转换为相应的基本类型值,如果返回的是非数字的基本类型值,则再遵循以上规则将其强制转换为数字。
为了将值转换为相应的基本类型值,抽象操作 ToPrimitive 会首先(通过内部操作 DefaultValue)检查该值是否有 valueOf () 方法。如果有并且返回基本类型值,就使用该值进行强制类型转换。如果没有就使用 toString () 的返回值(如果存在)来进行强制类型转换。
如果 valueOf () 和 toString () 均不返回基本类型值,会产生 TypeError 错误。
- 其他值到布尔类型的值的转换规则?
以下这些是假值: • undefined • null • false • +0、-0 和 NaN •
假值的布尔强制类型转换结果为 false。从逻辑上说,假值列表以外的都应该是真值。
- || 和 && 操作符的返回值?
|| 和 && 首先会对第一个操作数执行条件判断,如果其不是布尔值就先强制转换为布尔类型,然后再执行条件判断。
- 对于 || 来说,如果条件判断结果为 true 就返回第一个操作数的值,如果为 false 就返回第二个操作数的值。
- && 则相反,如果条件判断结果为 true 就返回第二个操作数的值,如果为 false 就返回第一个操作数的值。
|| 和 && 返回它们其中一个操作数的值,而非条件判断的结果
- Object.is () 与比较操作符
“===”、“==”的区别?
- 使用双等号(==)进行相等判断时,如果两边的类型不一致,则会进行强制类型转化后再进行比较。
- 使用三等号(===)进行相等判断时,如果两边的类型不一致时,不会做强制类型准换,直接返回 false。
- 使用 Object.is 来进行相等判断时,一般情况下和三等号的判断相同,它处理了一些特殊的情况,比如 -0 和 +0 不再相等,两个 NaN 是相等的。
- 什么是 JavaScript 中的包装类型?
在 JavaScript 中,基本类型是没有属性和方法的,但是为了便于操作基本类型的值,在调用基本类型的属性或方法时 JavaScript 会在后台隐式地将基本类型的值转换为对象,如:
const a = "abc"; | |
a.length; // 3 | |
a.toUpperCase(); // "ABC" |
在访问 'abc'.length 时,JavaScript 将 'abc' 在后台转换成 String ('abc'),然后再访问其 length 属性。
JavaScript 也可以使用 Object 函数显式地将基本类型转换为包装类型:
var a = 'abc' | |
Object(a) // String {"abc"} |
也可以使用 valueOf 方法将包装类型倒转成基本类型:
var a = 'abc' | |
var b = Object(a) | |
var c = b.valueOf() // 'abc' |
看看如下代码会打印出什么:
var a = new Boolean( false ); | |
if (!a) { | |
console.log( "Oops" ); // never runs | |
} |
答案是什么都不会打印,因为虽然包裹的基本类型是 false,但是 false 被包裹成包装类型后就成了对象,所以其非值为 false,所以循环体中的内容不会运行。
- JavaScript 中如何进行隐式类型转换?
首先要介绍 ToPrimitive 方法,这是 JavaScript 中每个值隐含的自带的方法,用来将值 (无论是基本类型值还是对象)转换为基本类型值。如果值为基本类型,则直接返回值本身;如果值为对象,其看起来大概是这样:
/** | |
* @obj 需要转换的对象 | |
* @type 期望的结果类型 | |
*/ | |
ToPrimitive(obj,type) |
type 的值为 number 或者 string。
(1)当 type 为 number 时规则如下:
- 调用 obj 的 valueOf 方法,如果为原始值,则返回,否则下一步;
- 调用 obj 的 toString 方法,后续同上;
- 抛出 TypeError 异常。
(2)当 type 为 string 时规则如下:
- 调用 obj 的 toString 方法,如果为原始值,则返回,否则下一步;
- 调用 obj 的 valueOf 方法,后续同上;
- 抛出 TypeError 异常。
p.s.
- toString 方法用于将对象转换为字符串。
- valueOf 方法用于返回对象的原始值。
可以看出两者的主要区别在于调用 toString 和 valueOf 的先后顺序。默认情况下:
- 如果对象为 Date 对象,则 type 默认为 string;
- 其他情况下,type 默认为 number。
总结上面的规则,对于 Date 以外的对象,转换为基本类型的大概规则可以概括为一个函数:
var objToNumber = value => Number(value.valueOf().toString()) | |
objToNumber([]) === 0 | |
objToNumber({}) === NaN |
而 JavaScript 中的隐式类型转换主要发生在 +、-、*、/ 以及 ==、>、< 这些运算符之间。而这些运算符只能操作基本类型值,所以在进行这些运算前的第一步就是将两边的值用 ToPrimitive 转换成基本类型,再进行操作。
以下是基本类型的值在不同操作符的情况下隐式转换的规则 (对于对象,其会被 ToPrimitive 转换成基本类型,所以最终还是要应用基本类型转换规则):
(1) + 操作符 + 操作符的两边有至少一个 string 类型变量时,两边的变量都会被隐式转换为字符串;其他情况下两边的变量都会被转换为数字。
1 + '23' // '123' | |
1 + false // 1 | |
1 + Symbol() // Uncaught TypeError: Cannot convert a Symbol value to a number | |
'1' + false // '1false' | |
false + true // 1 |
(2) -、*、\ 操作符
NaN 也是一个数字
1 * '23' // 23 | |
1 * false // 0 | |
1 / 'aa' // NaN |
(3) 对于 == 操作符
操作符两边的值都尽量转成 number:
3 == true //false, 3 转为 number 为 3,true 转为 number 为 1 | |
'0' == false //true, '0' 转为 number 为 0,false 转为 number 为 0 | |
'0' == 0 // '0' 转为 number 为 0 |
(4) 对于 < 和 > 比较符
如果两边都是字符串,则比较字母表顺序:
'ca' < 'bd' // false | |
'a' < 'b' // true |
其他情况下,转换为数字再比较:
'12' < 13 // true | |
false > -1 // true |
以上说的是基本类型的隐式转换,而对象会被 ToPrimitive 转换为基本类型再进行转换:
var a = {} | |
a > 2 // false |
其对比过程如下:
a.valueOf() // {}, 上面提到过,ToPrimitive 默认 type 为 number,所以先 valueOf,结果还是个对象,下一步 | |
a.toString() // "[object Object]",现在是一个字符串了 | |
Number(a.toString()) // NaN,根据上面 < 和 > 操作符的规则,要转换成数字 | |
NaN > 2 //false,得出比较结果 |
又比如:
var a = {name:'Jack'} | |
var b = {age: 18} | |
a + b // "[object Object][object Object]" |
运算过程如下:
a.valueOf() // {},上面提到过,ToPrimitive 默认 type 为 number,所以先 valueOf,结果还是个对象,下一步 | |
a.toString() // "[object Object]" | |
b.valueOf() // 同理 | |
b.toString() // "[object Object]" | |
a + b // "[object Object][object Object]" |
+操作符什么时候用于字符串的拼接?
根据 ES5 规范,如果某个操作数是字符串或者能够通过以下步骤转换为字符串的话,+ 将进行拼接操作。如果其中一个操作数是对象(包括数组),则首先对其调用 ToPrimitive 抽象操作,该抽象操作再调用 [[DefaultValue]],以数字作为上下文。如果不能转换为字符串,则会将其转换为数字类型来进行计算。
简单来说就是,如果 + 的其中一个操作数是字符串(或者通过以上步骤最终得到字符串),则执行字符串拼接,否则执行数字加法。
那么对于除了加法的运算符来说,只要其中一方是数字,那么另一方就会被转为数字。
- 为什么会有 BigInt 的提案?
JavaScript 中 Number.MAX_SAFE_INTEGER 表示最⼤安全数字,计算结果是 9007199254740991,即在这个数范围内不会出现精度丢失(⼩数除外)。但是⼀旦超过这个范围,js 就会出现计算不准确的情况,这在⼤数计算的时候不得不依靠⼀些第三⽅库进⾏解决,因此官⽅提出了 BigInt 来解决此问题。
- object.assign 和扩展运算法是深拷贝还是浅拷贝,两者区别
扩展运算符:
let outObj = { | |
inObj: {a: 1, b: 2} | |
} | |
let newObj = {...outObj} | |
newObj.inObj.a = 2 | |
console.log(outObj) // {inObj: {a: 2, b: 2}} |
Object.assign():
let outObj = { | |
inObj: {a: 1, b: 2} | |
} | |
let newObj = Object.assign({}, outObj) | |
newObj.inObj.a = 2 | |
console.log(outObj) // {inObj: {a: 2, b: 2}} |
可以看到,两者都是浅拷贝。
- Object.assign () 方法接收的第一个参数作为目标对象,后面的所有参数作为源对象。然后把所有的源对象合并到目标对象中。它会修改了一个对象,因此会触发 ES6 setter。
- 扩展操作符(…)使用它时,数组或对象中的每一个值都会被拷贝到一个新的数组或对象中。它不复制继承的属性或类的属性,但是它会复制 ES6 的 symbols 属性。
# 二、ES6
- let、const、var 的区别
(1)块级作用域: 块作用域由 { } 包括,let 和 const 具有块级作用域,var 不存在块级作用域。块级作用域解决了 ES5 中的两个问题:
- 内层变量可能覆盖外层变量
- 用来计数的循环变量泄露为全局变量
(2)变量提升: var 存在变量提升,let 和 const 不存在变量提升,即在变量只能在声明之后使用,否在会报错。
(3)给全局添加属性: 浏览器的全局对象是 window,Node 的全局对象是 global。var 声明的变量为全局变量,并且会将该变量添加为全局对象的属性,但是 let 和 const 不会。
(4)重复声明: var 声明变量时,可以重复声明变量,后声明的同名变量会覆盖之前声明的遍历。const 和 let 不允许重复声明变量。
(5)暂时性死区: 在使用 let、const 命令声明变量之前,该变量都是不可用的。这在语法上,称为暂时性死区。使用 var 声明的变量不存在暂时性死区。
(6)初始值设置: 在变量声明时,var 和 let 可以不用设置初始值。而 const 声明变量必须设置初始值。
(7)指针指向: let 和 const 都是 ES6 新增的用于创建变量的语法。 let 创建的变量是可以更改指针指向(可以重新赋值)。但 const 声明的变量是不允许改变指针的指向。
| 区别 | var | let | const |
|---|---|---|---|
| 是否有块级作用域 | × | ✔️ | ✔️ |
| 是否有变量提升 | ✔️ | × | × |
| 是否添加全局属性 | ✔️ | × | × |
| 能否重复声明变量 | ✔️ | × | × |
| 是否有暂时性死区 | × | ✔️ | ✔️ |
| 是否需要初始化 | × | ✔️ | ✔️ |
| 是否必须设置初始值 | × | × | ✔️ |
| 是否可以改变指针指向 | ✔️ | ✔️ | × |
- const 对象的属性可以修改吗
const 保证的并不是变量的值不能改动,而是变量指向的那个内存地址不能改动。对于基本类型的数据(数值、字符串、布尔值),其值就保存在变量指向的那个内存地址,因此等同于常量。
但对于引用类型的数据(主要是对象和数组)来说,变量指向数据的内存地址,保存的只是一个指针,const 只能保证这个指针是固定不变的,至于它指向的数据结构是不是可变的,就完全不能控制了。
- 如果 new 一个箭头函数会怎么样
箭头函数是 ES6 中的提出来的,它没有 prototype,也没有自己的 this 指向,更不可以使用 arguments 参数,所以不能 New 一个箭头函数。
new 操作符的实现步骤如下:
(1)创建一个对象
(2)将构造函数的作用域赋给新对象(也就是将对象的__proto__属性指向构造函数的 prototype 属性)
(3)执行构造函数中的代码,构造函数中的 this 指向该对象(也就是为这个对象添加属性和方法)
(4)返回新对象
所以,上面的第二、三步,箭头函数都是没有办法执行的。
- 箭头函数与普通函数的区别
(1)箭头函数比普通函数更加简洁
- 如果没有参数,就直接写一个空括号即可
- 如果只有一个参数,可以省去参数的括号
- 如果有多个参数,用逗号分割
- 如果函数体的返回值只有一句,可以省略大括号
- 如果函数体不需要返回值,且只有一句话,可以给这个语句前面加一个 void 关键字。最常见的就是调用一个函数:
let fn = () => void doesNotReturn(); |
(2)箭头函数没有自己的 this
箭头函数不会创建自己的 this, 所以它没有自己的 this,它只会在自己作用域的上一层继承 this。所以箭头函数中 this 的指向在它在定义时已经确定了,之后不会改变。
(3)箭头函数继承来的 this 指向永远不会改变
var id = 'GLOBAL'; | |
var obj = { | |
id: 'OBJ', | |
a: function() { | |
console.log(this.id); | |
}, | |
b: () => { | |
console.log(this.id); | |
} | |
}; | |
obj.a(); // 'OBJ' | |
obj.b(); // 'GLOBAL' | |
new obj.a() // undefined | |
new obj.b() // Uncaught TypeError: obj.b is not a constructor |
(b 是箭头函数,它的外层作用域是全局作用域,因此它的 this 被绑定到全局对象((在浏览器中是 window 对象,在 Node.js 中是 global 对象)))
对象 obj 的方法 b 是使用箭头函数定义的,这个函数中的 this 就永远指向它定义时所处的全局执行环境中的 this,即便这个函数是作为对象 obj 的方法调用,this 依旧指向 Window 对象。需要注意,定义对象的大括号 {} 是无法形成一个单独的执行环境的,它依旧是处于全局执行环境中。
(对象的大括号 {} 不会创建新的执行环境:它只是在当前的作用域中定义了一个对象字面量,所有的属性和方法都仍然是当前作用域的一部分。
函数会创建新的执行环境:定义一个函数时,函数内部会形成一个新的作用域,函数内部的变量和操作不会影响外部的作用域。)
(4)call ()、apply ()、bind () 等方法不能改变箭头函数中 this 的指向
var id = 'Global'; | |
let fun1 = () => { | |
console.log(this.id) | |
}; | |
fun1(); // 'Global' | |
fun1.call({id: 'Obj'}); // 'Global' | |
fun1.apply({id: 'Obj'}); // 'Global' | |
fun1.bind({id: 'Obj'})(); // 'Global' |
(5)箭头函数不能作为构造函数使用
构造函数在 new 的步骤在上面已经说过了,实际上第二步就是将函数中的 this 指向该对象。 但是由于箭头函数时没有自己的 this 的,且 this 指向外层的执行环境,且不能改变指向,所以不能当做构造函数使用。
(6)箭头函数没有自己的 arguments
箭头函数没有自己的 arguments 对象。在箭头函数中访问 arguments 实际上获得的是外层函数的 arguments。
(7)箭头函数没有 prototype
(8)箭头函数不能用作 Generator 函数,不能使用 yeild 关键字
- 箭头函数的 this 指向哪⾥?
箭头函数不同于传统 JavaScript 中的函数,箭头函数并没有属于⾃⼰的 this,它所谓的 this 是捕获其所在上下⽂的 this 值,作为⾃⼰的 this 值,并且由于没有属于⾃⼰的 this,所以是不会被 new 调⽤的,这个所谓的 this 也不会被改变。
可以⽤ Babel 理解⼀下箭头函数:
// ES6 | |
const obj = { | |
getArrow() { | |
return () => { | |
console.log(this === obj); | |
}; | |
} | |
} |
转化后:
// ES5,由 Babel 转译 | |
var obj = { | |
getArrow: function getArrow() { | |
var _this = this; | |
return function () { | |
console.log(_this === obj); | |
}; | |
} | |
}; |
- 扩展运算符的作用及使用场景
(1)对象扩展运算符
对象的扩展运算符 (...) 用于取出参数对象中的所有可遍历属性,拷贝到当前对象之中。
let bar = { a: 1, b: 2 }; | |
let baz = { ...bar }; // { a: 1, b: 2 } |
上述方法实际上等价于:
let bar = { a: 1, b: 2 }; | |
let baz = Object.assign({}, bar); // { a: 1, b: 2 } |
Object.assign 方法用于对象的合并,将源对象(source)的所有可枚举属性,复制到目标对象(target)。Object.assign 方法的第一个参数是目标对象,后面的参数都是源对象。(如果目标对象与源对象有同名属性,或多个源对象有同名属性,则后面的属性会覆盖前面的属性)。
同样,如果用户自定义的属性,放在扩展运算符后面,则扩展运算符内部的同名属性会被覆盖掉。
let bar = {a: 1, b: 2}; | |
let baz = {...bar, ...{a:2, b: 4}}; // {a: 2, b: 4} |
利用上述特性就可以很方便的修改对象的部分属性。在 redux 中的 reducer 函数规定必须是一个纯函数,reducer 中的 state 对象要求不能直接修改,可以通过扩展运算符把修改路径的对象都复制一遍,然后产生一个新的对象返回。
需要注意:扩展运算符对对象实例的拷贝属于浅拷贝。
(2)数组扩展运算符
数组的扩展运算符可以将一个数组转为用逗号分隔的参数序列,且每次只能展开一层数组。
console.log(...[1, 2, 3]) | |
// 1 2 3 | |
console.log(...[1, [2, 3, 4], 5]) | |
// 1 [2, 3, 4] 5 |
下面是数组的扩展运算符的应用:
- 将数组转换为参数序列
function add(x, y) { | |
return x + y; | |
} | |
const numbers = [1, 2]; | |
add(...numbers) // 3 |
- 复制数组
const arr1 = [1, 2]; | |
const arr2 = [...arr1]; |
要记住:扩展运算符 (…) 用于取出参数对象中的所有可遍历属性,拷贝到当前对象之中,这里参数对象是个数组,数组里面的所有对象都是基础数据类型,将所有基础数据类型重新拷贝到新的数组中。
- 合并数组
如果想在数组内合并数组,可以这样:
const arr1 = ['two', 'three'];const arr2 = ['one', ...arr1, 'four', 'five'];// ["one", "two", "three", "four", "five"] |
- 扩展运算符与解构赋值结合起来,用于生成数组
const [first, ...rest] = [1, 2, 3, 4, 5];first // 1rest // [2, 3, 4, 5] |
需要注意:如果将扩展运算符用于数组赋值,只能放在参数的最后一位,否则会报错。
const [...rest, last] = [1, 2, 3, 4, 5]; // 报错 const [first, ...rest, last] = [1, 2, 3, 4, 5]; // 报错 |
- 将字符串转为真正的数组
[...'hello'] // [ "h", "e", "l", "l", "o" ] |
- 任何 Iterator 接口的对象,都可以用扩展运算符转为真正的数组
比较常见的应用是可以将某些数据结构转为数组:
//arguments 对象 | |
function foo() { | |
const args = [...arguments]; | |
} |
用于替换 es5 中的 Array.prototype.slice.call (arguments) 写法。
- 使用 Math 函数获取数组中特定的值
const numbers = [9, 4, 7, 1]; | |
Math.min(...numbers); // 1 | |
Math.max(...numbers); // 9 |
- 对对象与数组的解构的理解
解构是 ES6 提供的一种新的提取数据的模式,这种模式能够从对象或数组里有针对性地拿到想要的数值。 1)数组的解构 在解构数组时,以元素的位置为匹配条件来提取想要的数据的:
const [a, b, c] = [1, 2, 3] |
最终,a、b、c 分别被赋予了数组第 0、1、2 个索引位的值:
数组里的 0、1、2 索引位的元素值,精准地被映射到了左侧的第 0、1、2 个变量里去,这就是数组解构的工作模式。还可以通过给左侧变量数组设置空占位的方式,实现对数组中某几个元素的精准提取:
const [a,,c] = [1,2,3] |
通过把中间位留空,可以顺利地把数组第一位和最后一位的值赋给 a、c 两个变量
2)对象的解构 对象解构比数组结构稍微复杂一些,也更显强大。在解构对象时,是以属性的名称为匹配条件,来提取想要的数据的。现在定义一个对象:
const stu = { | |
name: 'Bob', | |
age: 24 | |
} |
假如想要解构它的两个自有属性,可以这样:
const { name, age } = stu |
这样就得到了 name 和 age 两个和 stu 平级的变量:
注意,对象解构严格以属性名作为定位依据,所以就算调换了 name 和 age 的位置,结果也是一样的:
const { age, name } = stu |
- 如何提取高度嵌套的对象里的指定属性?
有时会遇到一些嵌套程度非常深的对象:
const school = { | |
classes: { | |
stu: { | |
name: 'Bob', | |
age: 24, | |
} | |
} | |
} |
像此处的 name 这个变量,嵌套了四层,此时如果仍然尝试老方法来提取它:
const { name } = school |
显然是不奏效的,因为 school 这个对象本身是没有 name 这个属性的,name 位于 school 对象的 “儿子的儿子” 对象里面。要想把 name 提取出来,一种比较笨的方法是逐层解构:
const { classes } = school | |
const { stu } = classes | |
const { name } = stu | |
name // 'Bob' |
但是还有一种更标准的做法,可以用一行代码来解决这个问题:
const { classes: { stu: { name } }} = school | |
console.log(name) // 'Bob' |
可以在解构出来的变量名右侧,通过冒号 +{目标属性名} 这种形式,进一步解构它,一直解构到拿到目标数据为止。
- 对 rest 参数的理解
扩展运算符被用在函数形参上时,它还可以把一个分离的参数序列整合成一个数组:
function mutiple(...args) { | |
let result = 1; | |
for (var val of args) { | |
result *= val; | |
} | |
return result; | |
} | |
mutiple(1, 2, 3, 4) // 24 |
这里,传入 mutiple 的是四个分离的参数,但是如果在 mutiple 函数里尝试输出 args 的值,会发现它是一个数组:
function mutiple(...args) { | |
console.log(args) | |
} | |
mutiple(1, 2, 3, 4) // [1, 2, 3, 4] |
这就是 … rest 运算符的又一层威力了,它可以把函数的多个入参收敛进一个数组里。这一点经常用于获取函数的多余参数,或者像上面这样处理函数参数个数不确定的情况。
- ES6 中模板语法与字符串处理
ES6 提出了 “模板语法” 的概念。在 ES6 以前,拼接字符串是很麻烦的事情:
var name = 'css' | |
var career = 'coder' | |
var hobby = ['coding', 'writing'] | |
var finalString = 'my name is ' + name + ', I work as a ' + career + ', I love ' + hobby[0] + ' and ' + hobby[1] |
仅仅几个变量,写了这么多加号,还要时刻小心里面的空格和标点符号有没有跟错地方。但是有了模板字符串,拼接难度直线下降:
var name = 'css' | |
var career = 'coder' | |
var hobby = ['coding', 'writing'] | |
var finalString = `my name is ${name}, I work as a ${career} I love ${hobby[0]} and ${hobby[1]}` |
字符串不仅更容易拼了,也更易读了,代码整体的质量都变高了。这就是模板字符串的第一个优势 —— 允许用 ${} 的方式嵌入变量。但这还不是问题的关键,模板字符串的关键优势有两个:
- 在模板字符串中,空格、缩进、换行都会被保留
- 模板字符串完全支持 “运算” 式的表达式,可以在 ${} 里完成一些计算
基于第一点,可以在模板字符串里无障碍地直接写 html 代码:
let list = ` | |
<ul> | |
<li>列表项1</li> | |
<li>列表项2</li> | |
</ul> | |
`; | |
console.log(message); // 正确输出,不存在报错 |
基于第二点,可以把一些简单的计算和调用丢进 ${} 来做:
function add(a, b) { | |
const finalString = `${a} + ${b} = ${a+b}` | |
console.log(finalString) | |
} | |
add(1, 2) // 输出 '1 + 2 = 3' |
除了模板语法外, ES6 中还新增了一系列的字符串方法用于提升开发效率:
(1)存在性判定:在过去,当判断一个字符 / 字符串是否在某字符串中时,只能用 indexOf > -1 来做。现在 ES6 提供了三个方法:includes、startsWith、endsWith,它们都会返回一个布尔值来告诉你是否存在。
- includes:判断字符串与子串的包含关系:
const son = 'haha' | |
const father = 'xixi haha hehe' | |
father.includes(son) // true |
- startsWith:判断字符串是否以指定子串开头:
const father = 'xixi haha hehe' | |
father.startsWith('haha') // false | |
father.startsWith('xixi') // true |
- endsWith:判断字符串是否以指定子串结尾:
const father = 'xixi haha hehe' | |
father.endsWith('hehe') // true |
(2)自动重复:可以使用 repeat 方法来使同一个字符串输出多次(被连续复制多次):
const sourceCode = 'repeat for 3 times;' | |
const repeated = sourceCode.repeat(3) | |
console.log(repeated) // repeat for 3 times;repeat for 3 times;repeat for 3 times; |